
 Expectations from today’s business environment are high availability, continuous operation and quick disaster recovery. For these reasons, enterprises and partners try to increase their ability to respond to risks. Although it is more difficult, they also try to utilize opportunities.
Expectations from today’s business environment are high availability, continuous operation and quick disaster recovery. For these reasons, enterprises and partners try to increase their ability to respond to risks. Although it is more difficult, they also try to utilize opportunities.
There are some items an enterprise should decide on. First of them is acceptable level of data loss. How much data loss is acceptable? A few seconds? A few minutes? Half an hour? Data entered before disaster and after last consistent backup will be lost. This period is called Recovery Point Objective (RPO). This data should be entered manually after recovery. This period should not be longer than some fraction of seconds for financial enterprises.
Another period in disaster recovery timeline an enterprise will decide is how long it will take to start business after a disaster. This period is called Recovery Time Objective (RTO).
If RTO is in minutes, it will cost a fortune. If RTO is some hours, cost will be less. Cost will be less and less if RTO is set longer.
 There are some periods of time related with disaster recovery. When an unexpected event or incident is occurred management of enterprise should decide whether this incident is a disaster or not. Since a capital goods investment is needed to recover disaster, approval of management is required. To decide whether an incident is disaster or not, management would need information related with damage. So a damage assessment is required and it takes some time. It also takes some time to start damage assessment after incident occurs. Finally it takes some time for disaster assessment after damage assessment. Sum of these time intervals is called Maximum Tolerable Period of Downtime (MTPOD) or Maximum Tolerable Outage (MTO). Beyond this point, enterprise is out of business.
There are some periods of time related with disaster recovery. When an unexpected event or incident is occurred management of enterprise should decide whether this incident is a disaster or not. Since a capital goods investment is needed to recover disaster, approval of management is required. To decide whether an incident is disaster or not, management would need information related with damage. So a damage assessment is required and it takes some time. It also takes some time to start damage assessment after incident occurs. Finally it takes some time for disaster assessment after damage assessment. Sum of these time intervals is called Maximum Tolerable Period of Downtime (MTPOD) or Maximum Tolerable Outage (MTO). Beyond this point, enterprise is out of business.
To define these periods logically, an enterprise should evaluate what it will lose in case of outage and impacts to the business:
- Lost revenue, loss of cash flow, and loss of profits
- Loss of clients (lifetime value of each) and market share
- Fines, penalties, and liability claims for failure to meet regulatory compliance
- Lost ability to respond to subsequent marketplace opportunities
- Cost of re-creation and recovery of lost data
- Salaries paid to staff unable to undertake billable work
- Salaries paid to staff to recover work backlog and maintain deadlines
- Employee idleness, labor cost, and overtime compensation
- Lost market share, loss of share value, and loss of brand image; etc.
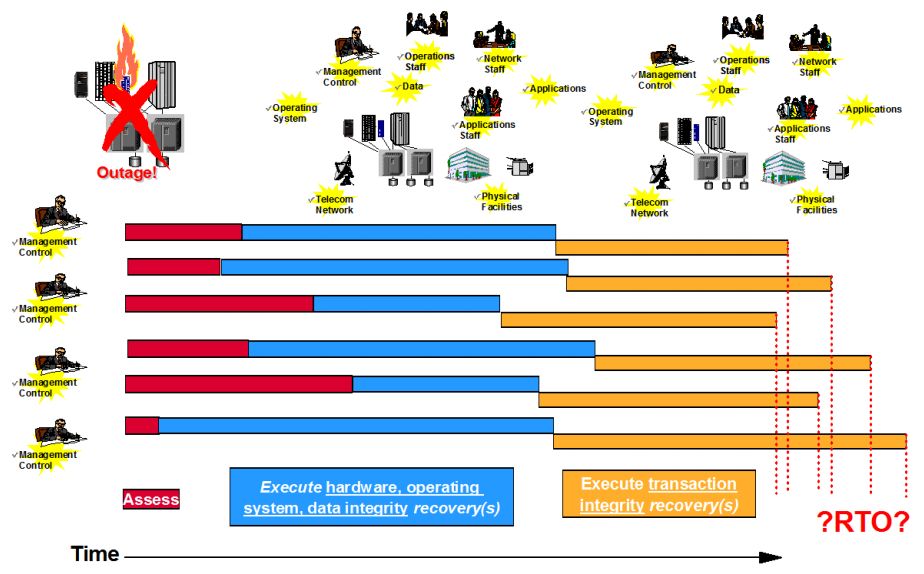
 Components causing outage in a disaster are servers, storage devices, network components, software and infrastructural components like power. Recovery can be decomposed into hardware recovery, data integrity and data consistency.
Components causing outage in a disaster are servers, storage devices, network components, software and infrastructural components like power. Recovery can be decomposed into hardware recovery, data integrity and data consistency.
Hardware recovery is making hardware, operating systems and network connections available. All storage devices and network components should be up, operating systems should be running. Data integrity can be considered as part of hardware recovery or it can be considered as a separate item.
This point is a bit confusing. Most of IT staff tend to claim that “Everything is up and running” but this is not the case. Data is not recovered from users’ standpoint. Application and data consistency should be attained. Applications should be recovered from most recent version backups. Data base resources should be restored from last image copy backups, log changes should be applied. A database restart should be performed. It is hoped that long and unpredictable database recovery will not take place. Just a few incomplete logical unit of works (luws) may be rolled back. After these activities, transaction integrity will be okay.
 Recovery Consistency Objective (RCO) is another concept related with business continuity. It focuses on data consistency achieved after disaster recovery. 100% RCO denotes all transaction entities are consistent after disaster recovery, any target below this amount means that the enterprise tolerates some data inconsistencies.
Recovery Consistency Objective (RCO) is another concept related with business continuity. It focuses on data consistency achieved after disaster recovery. 100% RCO denotes all transaction entities are consistent after disaster recovery, any target below this amount means that the enterprise tolerates some data inconsistencies.
Single most critical factor affecting successful disaster recovery is avoiding labor intensive and unpredictable duration application and data base recovery. They should be fast, repeatable and consistent.
Rolling disasters should be another consideration in successful business continuity. Disasters may spread out over time. Partial damages may not be recognized on time, as time passes, they cause problems but it may be too late. Databases for example restarted but long recovery takes place due to inconsistencies and further loss of data recurs.
Some enterprises have heterogeneous platforms. If this is the case, there would be duplicate work for all platforms. Additionally assessments, hardware recovery and transaction recovery times are different for all platforms. This situation could be very difficult to coordinate and very complex to manage.
 After disaster recovery planning is completed, it is implemented. Implementation involves setting policies, material acquisition, staffing and testing. Periodical tests should include swinging from primary site to secondary site and vice versa. After completing implementation, periodical maintenance takes place and frequent testing should accompany maintenance for successful disaster recovery.
After disaster recovery planning is completed, it is implemented. Implementation involves setting policies, material acquisition, staffing and testing. Periodical tests should include swinging from primary site to secondary site and vice versa. After completing implementation, periodical maintenance takes place and frequent testing should accompany maintenance for successful disaster recovery.
